Key concepts
- Solving nonlinear algebraic equations
- Systems of equations
- Degrees of freedom
- Slicing lists
- Arrays
- fsolve
Introduction
When analysing plant data, rarely are we provided with all rate and composition data. Instrumentation, sampling and laboratory analysis can be expensive and we need to make best use of available information to infer data for which we don’t have measurements. In this post we will look at an example where we exactly the minimum amount of the information to complete the mass balance across a system of 3 separation columns. In a later post, we will look at managing situation when we have either too many or too few measurements to complete the mass balance.
Problem description
The problem for this post is the 2nd example taken from the collection originally distributed at the ASEE Chemical Engineering Summer School held in Snowbird, Utah on August 13, 1997. This problem involves an array of 3 distillation columns separating xylene, styrene, toluene and benzene. The arrangement of the columns and the names for all the streams are shown in the following diagram.

We are given the molar flowrate for stream F (=70 mol/min) and molar fraction for all 4 components in streams F, D1, B1, D2 and B2.
| Stream | Xylene | Styrene | Toluene | Benzene |
| F | 15% | 25% | 40% | 20% |
| D1 | 7% | 4% | 54% | 35% |
| B1 | 18% | 24% | 42% | 16% |
| D2 | 15% | 10% | 54% | 21% |
| B2 | 24% | 65% | 10% | 1% |
We are then asked to provide the following information:
- Molar flowrates for product streams
- Compositions and molar flowrates of the intermediate streams
It is possible to solve this problem separately in these 2 steps. However, in this blog we will create a single system description which will provide molar flowrates and compositions for all streams at the same time.
Degrees of Freedom
Understanding the degrees of freedom is critical for a problem like this. It may not be immediately obvious wether or not we have enough, too little or too much information. In fact in this case the problem is over specified by 5 results, but I am getting ahead of myself.
First of all, how many variables do we have? For each stream there are 5 variables = 4 molar fractions + 1 molar flowrate. Also, there are 7 streams = 1 feed + 2 intermediate + 4 product streams. So in total there are 35 variables.
How many equations do we have? Before describing the equations, we can use the following logic. For each distillation column, there are 4 mass balances, corresponding to each of xylene, styrene, toluene and benzene (note – this purely a physical separation and there are no chemical reactions). So over the 3 columns, there are 12 mass balance equations. In addition we can assume that there are no other chemicals involved so that the molar fractions for each stream must sum to 1. This creates an additional 7 equations.
Finally, as described above we have been given 21 pieces of information = 20 molar fractions and 1 molar flowrate.
So our degrees of freedom = 35 – (12 + 7) – 21 = -5. Or in other words it has been over specified by 5 variables. This is because we are given all molar fractions for each of the 5 streams, when we could in theory calculate the fourth fraction given only 3. So the problem is only trivially over specified. In otherwords, we can only use the additional 5 data points to check that the supplied molar fractions sum to 1. As they do, we really have a exactly specified problem.
Describing the mass balance
In this blog, we will deviation from the problem description in the original paper. Instead, we will take advantage of python’s ability to use vectors, to create a simpler, more generic and frankly more robust description.
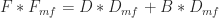
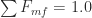
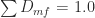
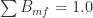
- F, D, B = molar flowrates, mol/min, for streams F, D and B
- F_mf, D_mf, B_mf = vector of mole fractions for streams F, D and B
The first equation represents 4 different equations, corresponding to the 4 chemical components. Also, this set of equations is repeated for each of the 3 distillation columns.
What type of problem
As with the case study 1 (previous blog post) we have a number of nonlinear algebraic equations to be solved. Algebraic because there are no differential terms. In this case the the equations are nonlinear because they involve multiplication of different variables for which we are seeking a solution (e.g 
Knowing this, our general approach for solving will be:
- Define known variables
- Create a function containing all equations in difference form (i.e. LSH – RHS)
- Solve using a routine for finding the roots of equations (in this case fsolve)
The solution
To begin with here is the full solution, produced using python through a Jupyter notebook.
Initialising
As with all of our python solutions, we begin by specifying the individual packages we will need.
import numpy as np
from scipy.optimize import fsolveThis time we will use the following familiar packages (also used in the post for Case 1).
- numpy – a very powerful library of mathmatical routines
- scipy – an extensive library of mathematical analysis routines
We then continue by specifying the known molar flowrate for stream F and mole fractions for the feed stream and 4 product streams.
F = 70.0
F_mf = np.array([0.15, 0.25, 0.40, 0.20])
D1_mf = np.array([0.07, 0.04, 0.54, 0.35])
B1_mf = np.array([0.18, 0.24, 0.42, 0.16])
D2_mf = np.array([0.15, 0.10, 0.54, 0.21])
B2_mf = np.array([0.24, 0.65, 0.10, 0.01])As mentioned above we are going to use vectors to represent the set of mole fractions for each stream. This is done first of all by creating a python list – i.e. a list of items separated by comma and contained in square brackets. This list is then converted to an array using the numpy function called array. However, rather than doing this as 2 steps, this is all done in a single line of code. The numbers in the code should correspond to the table in the original problem specification.
Finally we need to specify initial guesses for all the remaining variables.
D,B,D1,B1,D2,B2 = [10.0]*6
D_mf = np.array([0.1]*4)
B_mf = np.array([0.1]*4)The code takes advantage of some of the syntax shortcuts available in python. In this case, all of the unknown molar flowrates are initialised to 10.0 mol/min in a single line of code (note: the code [10.0]*6 creates a list containing 6 values of 10.0 = [10.0, 10.0, 10.0, 10.0, 10.0, 10.0]).
Similarly the mole fractions for the intermediate streams are all initialised to 0.1 and put into an array.
The mass balance
The heart of the solution is contained in the next bit of code, which describes the model equations:
error_1 = 1 - sum(D_mf)
error_2 = 1 - sum(B_mf)
error_mf_1 = D *D_mf + B *B_mf - F*F_mf
error_mf_2 = D1*D1_mf + B1*B1_mf - D*D_mf
error_mf_3 = D2*D2_mf + B2*B2_mf - B*B_mfThese equations are the mass balances for the 3 distillation columns and the specification that the mole fractions must sum to 1.0 for the unspecified streams. Also the equations are written as a difference between the left hand side and right hand side that they can be solved through numerical solution.
These equations need to contained in function which will be called by fsolve. We have 14 variables which need to be solved for and they all need to be wrapped into a single list to be passed by the fsolve function. To do this we create a function called mass_balance which accepts an argument x. It is x which is a list containing the 14 variables. However, we need to split x apart so that it fits into out mass balance equations.
def mass_balance(x):
D, B, D1, B1, D2, B2 = x[0:6]
D_mf = np.array(x[6:10])
B_mf = np.array(x[10:15])
error_1 = 1 - sum(D_mf)
error_2 = 1 - sum(B_mf)
error_mf_1 = D *D_mf + B *B_mf - F*F_mf
error_mf_2 = D1*D1_mf + B1*B1_mf - D*D_mf
error_mf_3 = D2*D2_mf + B2*B2_mf - B*B_mf
return np.append([error_1, error_2], [error_mf_1, error_mf_2, error_mf_3])You can see that this is done by using the notation x[start_position, final_position]. However, this highlights 2 conventions that you need to get used to with python:
- The first position in python is always referenced by 0 (not 1)
- In sequences the final position is not included
So x[0:6] actually slices out the first 6 elements of the list x. That is x[0], x[1], x[2], x[3], x[4] and x[5]. Equivalently, x[6:10] slices out 4 elements starting from the 7th position. That is x[6], x[7], x[8] and x[9].
Depending on you background this may at first be confusing. Take some time to remember this as it is used throughout python and is simple once you get used to it!
Finally, the function returns the 14 unknown variables grouped together into a single list. The order of this list does not have to relate to the order of variables contained in x, but there does need to be the same number (i.e. the degrees of freedom).
Solving the equations
Now that the problem has been properly specified, the code to solve the problem is relatively simple as it uses the power of the fsolve routine.
solution = fsolve(mass_balance, np.append([D, B, D1, B1, D2, B2],[D_mf, B_mf]))
D, B, D1, B1, D2, B2 = solution[0:6]
D_mf = solution[6:10]
B_mf = solution[10:15]This code calls the routine fsolve and tells it to use the model contained in our function, mass_balance and uses the initial values we set for the molar flowrates and mole fractions. It returns the numerical result as a list to the variable solution. From here we slice out the values for the molar flowrates and mole fractions.
Finally we are able to display the results. It is always worth sense checking the results. In this case a quick check of the following all works out:
- Flows in and out of each column are equal
- Mole fractions sum to 1.0 on each stream
- Random selection of chemicals in and out of a column (e.g. xylene in and out of column 1) are equal
Sense checking and interpretation
Let’s do a quick sense check on the results to ensure that there is nothing obviously wrong with our solution.
- Results are all positive (check)
- Molar flowrates sum across each column (check)
- Mole fractions sum to 1.0 for each stream (check)
- Random selection of individual mass balances are correct (check)
- Flowrates are matching the reporting location of different chemicals – e.g. F is high in toluene, D is also high in toluene and the majority of the florwate goes to D as expected (check)
